I have Windows 7 installation, and try to dual boot with FreeBSD 9. Then problem occurs and fail to create the BSD. and then the Windows 7 cannot boot either. The windows partition is still not touched, but cannot boot to windows.
So the question was how to repair the Windows 7 Master Boot Record (MBR) ?
After search on google, there are solution to repair it using the windows 7 instalation disk.
Here are the step done and documented :
1. Boot to the Windows 7 installation disk

2. Select the Install Now

3. Select the recovery mode

4. Select the command prompt options.

5. Then you got some msdos prompt like :
x:\windows\system32>
6. Then type : dispkart and press enter
7. Type : select disk 0 and press enter
8. Type : list volume and press enter
9.There will be a list of volume, search for your windows 7 cdrom drive letter.
10. Then type : exit and press enter
11. Then go to your windows 7 dvd drive , if it is g then go to g: by type G: and then enter
12. Then type cd boot
13. Then to restore your MBR do this :
bootsect /nt60 SYS /mbr and press enter
14. Then you will be informed about the BOOTMGR volume update.
15. Then exit the msdos, and reboot/ restart.
Don't forget eject your DVD, and your windows7 will be boot and can be use again.
Welcome back to the windows.
So the question was how to repair the Windows 7 Master Boot Record (MBR) ?
After search on google, there are solution to repair it using the windows 7 instalation disk.
Here are the step done and documented :
1. Boot to the Windows 7 installation disk

2. Select the Install Now

3. Select the recovery mode

4. Select the command prompt options.
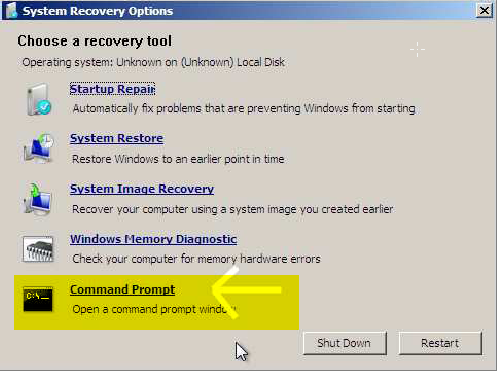
5. Then you got some msdos prompt like :
x:\windows\system32>
6. Then type : dispkart and press enter
7. Type : select disk 0 and press enter
8. Type : list volume and press enter
9.There will be a list of volume, search for your windows 7 cdrom drive letter.
10. Then type : exit and press enter
11. Then go to your windows 7 dvd drive , if it is g then go to g: by type G: and then enter
12. Then type cd boot
13. Then to restore your MBR do this :
bootsect /nt60 SYS /mbr and press enter
14. Then you will be informed about the BOOTMGR volume update.
15. Then exit the msdos, and reboot/ restart.
Don't forget eject your DVD, and your windows7 will be boot and can be use again.
Welcome back to the windows.